
Python Plotly and GPT-4: Engineering Beautiful Maps for Kicks
A modular prompting approach to maximize Python Plotly coding productivity

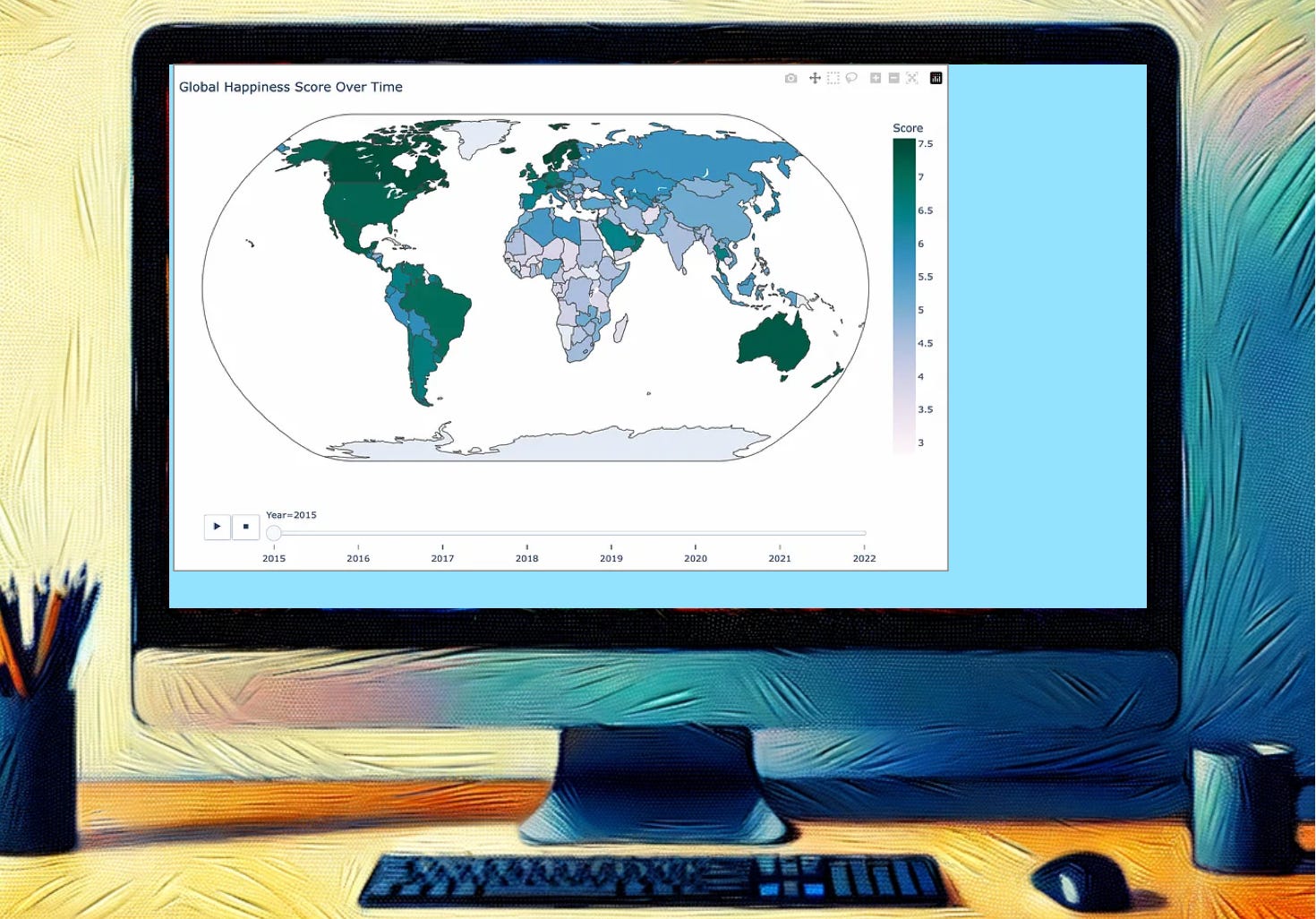
Modular prompt engineering with GPT-4 for Python code generation is highly efficient method for generating complex data visualization code, such as choropleth maps.
This approach saves time, effort, and reduces the complexity traditionally associated with crafting such maps. It’s so easy, you can do it just for fun!
Keep reading with a 7-day free trial
Subscribe to Data at Depth to keep reading this post and get 7 days of free access to the full post archives.