
Optimal Python Results: Why Dash Is Better Than Streamlit For Async Mapping
An interactive Python tutorial with the Canada large forest fire data set

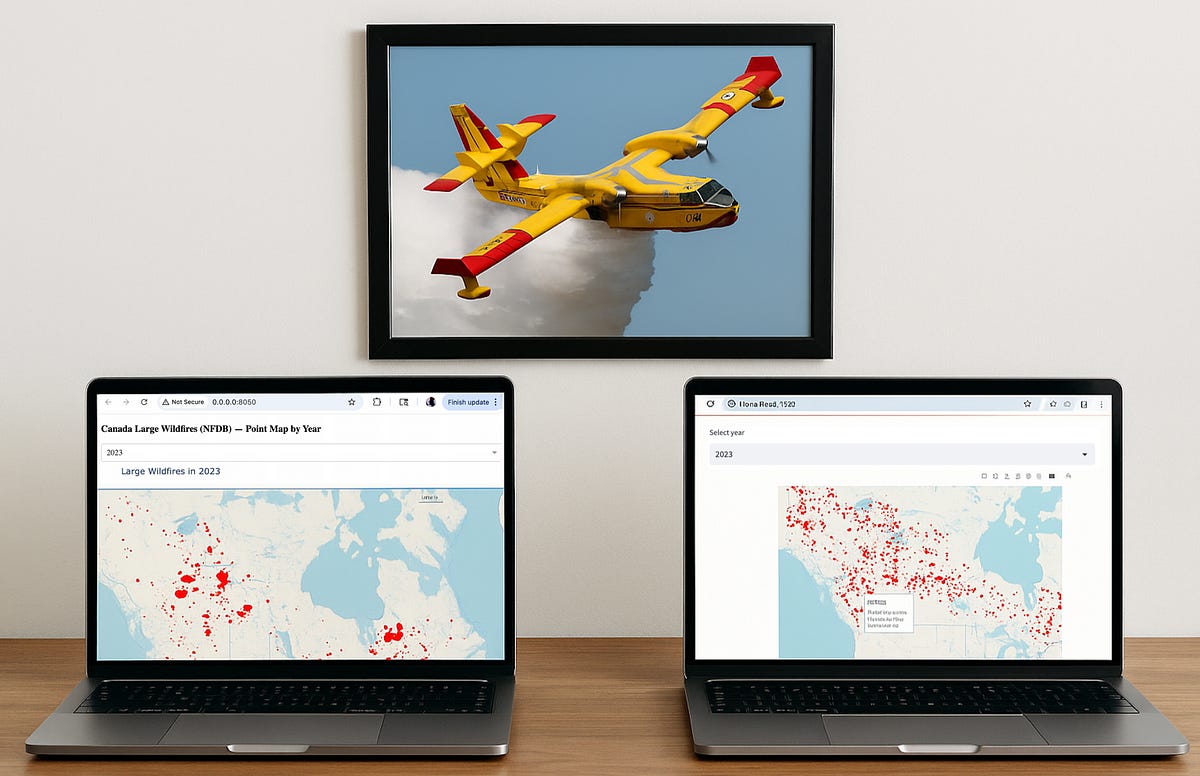
Interactive geographic maps often require filtering large datasets on demand.
Visualizing thousands of geospatial points in a web app is no small feat.
As an example, today I want to map all historical fires in Canada usin…
